做站这么久感触最深的就是原创文章在搜索引擎的眼里越来越重要。本人负责几个企业站的seo日常优化工作,其中一个站本来日均ip都在两三千,可由于某段时间网站内容质量不过关,导致网站被降权,长尾关键词的流量一下子去了一大半,网站流量也是差了近半。随着本人努力的原创,站点现在表现良好逐渐恢复稳定。在这个“内容为王”的时代,想要网站在搜索引擎中有好的表现,就必须在内容上苦下功夫。
可是众多seo人员深有体会,持久保持原创内容的建设并不是一件容易的事。于是伪原创、抄袭等各类招数就被站长们纷纷用上,这些方法真的有效还是自欺欺人?今天笔者就和大家一起分享搜索引擎对于重复内容判定方面的知识。
一、搜索引擎为何要积极处理重复内容?
1、节省爬取、索引、分析内容的空间和时间
用一句简单的话来讲就是,搜索引擎的资源是有限的,而用户的需求却是无限的。大量重复内容消耗着搜索引擎的宝贵资源,因此从成本的角度考虑必须对重复内容进行处理。
2、有助于避免重复内容的反复收集
从已经识别和收集到的内容中汇总出最符合用户查询意图的信息,这既能提高效率,也能避免重复内容的反复收集。
3、重复的频率可以作为优秀内容的评判标准
既然搜索引擎能够识别重复内容当然也就可以更有效的识别哪些内容是原创的、优质的,重复的频率越低,文章内容的原创优质度就越高。
4、改善用户体验
其实这也是搜索引擎最为看重的一点,只有处理好重复内容,把更多有用的信息呈递到用户面前,用户才能买账。
二、搜索引擎眼中重复内容都有哪些表现形式?
1、格式和内容都相似。这种情况在电商网站上比较常见,盗图现象比比皆是。
2、仅格式相似。
3、仅内容相似。
4、格式与内容各有部分相似。这种情况通常比较常见,尤其是企业类型网站。
三、搜索引擎如何判断重复内容?
1、通用的基本判断原理就是逐个对比每个页面的数字指纹。这种方法虽然能够找出部分重复内容,但缺点在于需要消耗大量的资源,操作速度慢、效率低。
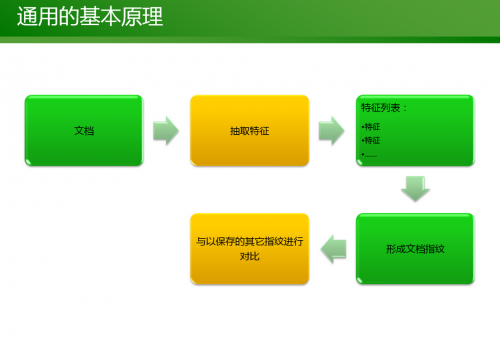
2、基于全局特征的I-Match
这种算法的原理是,将文本中出现的所有词先排序再打分,目的在于删除文本中无关的关键词,保留重要关键词。这样的方式去重效果效果高、效果明显。比如我们在伪原创时可能会把文章词语、段落互换,这种方式根本欺骗不了I-Match算法,它依然会判定重复。
3、基于停用词的Spotsig
文档中如过使用大量停用词,如语气助词、副词、介词、连词,这些对有效信息会造成干扰效果,搜索引擎在去重处理时都会对这些停用词进行删除,然后再进行文档匹配。因此,我们在做优化时不妨减少停用词的使用频率,增加页面关键词密度,更有利于搜索引擎抓取。

4、基于多重Hash的Simhash
这种算法涉及到几何原理,讲解起来比较费劲,简单说来就是,相似的文本具有相似的hash值,如果两个文本的simhash越接近,也就是汉明距离越小,文本就越相似。因此海量文本中查重的任务转换为如何在海量simhash中快速确定是否存在汉明距离小的指纹。我们只需要知道通过这种算法,搜索引擎能够在极短的时间内对大规模的网页进行近似查重。目前来看,这种算法在识别效果和查重效率上相得益彰。
来源:http://www.400kls.com