搜索引擎通过抓取和索引网页内容,使用户能够在搜索结果中找到他们所需的信息。然而,并非所有网页都希望被搜索引擎抓取和索引。这就是为什么有一个称为”robots.txt”的文件存在的原因。那么robots.txt文件是什么?怎么写?下面一起来看看。
一、robots.txt文件简介
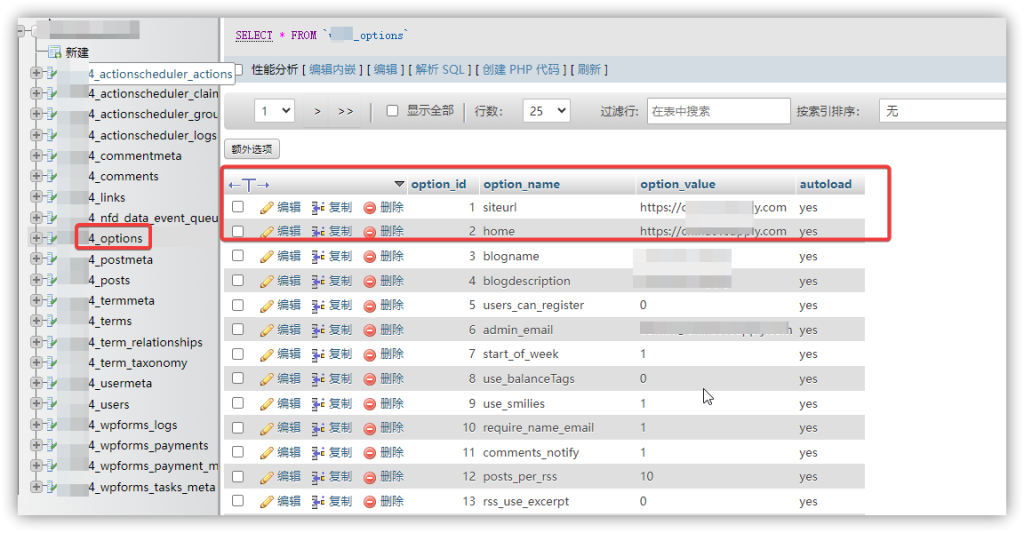
robots.txt是一个文本文件,通常放置在网站的根目录下,用于告诉搜索引擎爬虫哪些页面可以访问,哪些页面不能访问。通过遵循robots.txt文件中的规则,搜索引擎爬虫能够更加智能地抓取网站内容,从而提高网站在搜索引擎中的排名和曝光度。
二、robots.txt文件作用
1、节省带宽和服务器资源:通过限制爬虫对特定页面的访问,可以减少服务器的负担,节省带宽资源。
2、保护敏感信息:对于包含敏感信息的页面,如用户数据、后台管理页面等,可以通过robots.txt文件禁止爬虫访问,从而保护网站安全。
3、定制爬虫行为:管理员可以通过robots.txt文件为不同的搜索引擎爬虫设置不同的抓取策略,以满足特定需求。
三、如何编写robots.txt文件
1、文件格式:robots.txt文件使用纯文本格式,通常使用UTF-8编码。文件名必须为“robots.txt”,且应放置在网站的根目录下。
2、基本结构:robots.txt文件的基本结构包括用户代理(User-agent)和访问规则(Disallow)。每个规则占一行,以冒号(:)分隔键和值。
示例:
User-agent: * Disallow: /admin/ Disallow: /private/
上述示例中,User-agent: *表示该规则适用于所有搜索引擎爬虫。Disallow: /admin/和Disallow: /private/则分别表示禁止爬虫访问网站的“/admin/”和“/private/”目录下的所有页面。
3、自定义规则:除了基本的访问规则外,还可以根据需要添加其他自定义规则。例如,可以针对特定的搜索引擎爬虫设置不同的抓取策略,或者允许爬虫访问特定页面。
示例:
makefile User-agent: Googlebot Disallow: /archive/ User-agent: Bingbot Allow: /
上述示例中,针对Google爬虫,禁止访问“/archive/”目录下的所有页面;而针对Bing爬虫,则允许访问网站的所有页面。
4、测试与验证:编写完robots.txt文件后,应使用搜索引擎的爬虫模拟工具或在线验证工具进行测试,以确保文件的有效性。同时,也可以查看搜索引擎的爬虫日志,以了解它们是否遵循了robots.txt文件中的规则。
-

广告合作
-

QQ群号:4114653