近日AI圈又一火爆消息,小红书智创音频技术团队近日推出了新一代对话合成模型——FireRedTTS-2,专注于多说话人对话生成!目前支持4个说话人的3分钟对话生成,可以通过扩展训练语料进一步延长对话时长和增加说话人数量。
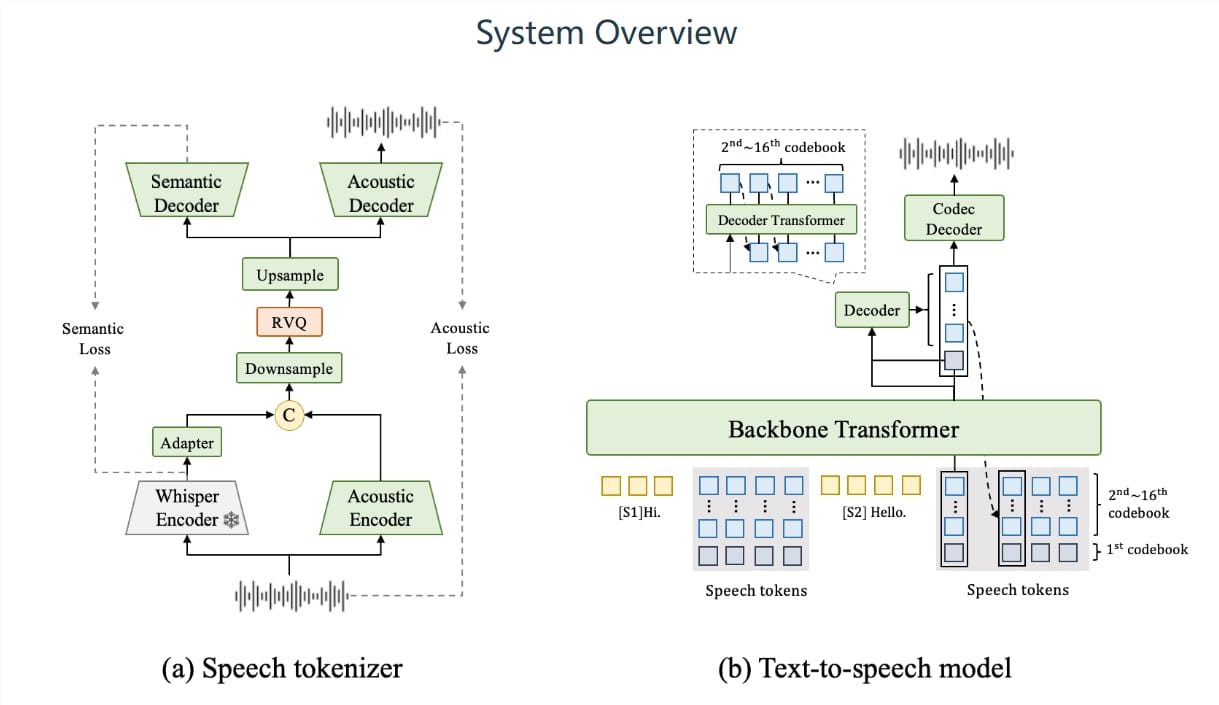
FireRedTTS-2是一款面向多说话者对话生成的长篇流式文本转语音(TTS)系统,具备长对话语音生成能力和广泛的多语言支持,还能够超低延迟流式生成,支持改变音色,解决现有对话合成方案中存在的一些痛点,例如灵活性差、发音错误频繁、说话人切换不稳定以及韵律自然度不足等问题。
FireRedTTS-2通过升级其核心模块,特别是离散语音编码器和文本语音合成模型,全面提升了合成效果。在多项主客观评测中,FireRedTTS-2均显示出行业领先水平,为多说话人的对话合成提供了更优的解决方案。其技术报告已在arXiv上发布,并可通过专用 Demo 和代码链接进行体验。
FireRedTTS-2的一个显著特点是其合成的自然度,模型能对重音、情绪和停顿等细节进行精确把握,音质自然流畅。与闭源的对话生成模型相比,FireRedTTS-2不仅能够生成高质量的播客音频,还支持音色克隆功能。只需提供每个发音人的一句语音样本,模型就可以模仿其音色和说话习惯,自动生成整段对话。这种功能使得其在开源对话生成领域具备了很强的竞争力。
在训练过程中,FireRedTTS-2不仅支持多语言(包括中文、英语、日语、韩语和法语),还利用低帧率的离散语音编码器提高了合成的速度与稳定性。同时,采用双 Transformer 的模型架构,使得合成语音更自然、更连贯。此外,FireRedTTS-2只需少量数据即可实现音色定制,快速适应不同的应用场景。
总结下来,FireRedTTS-2主要功能如下:
1、长对话语音生成:支持4个说话人的3分钟对话生成,可扩展训练语料以增加对话时长和说话人数量。
2、多语言支持:涵盖英语、中文、日语、韩语、法语、德语、俄语等,具备零样本跨语言及语码转换语音克隆能力。
3、低延迟与高保真:在L20 GPU环境下,首次数据包延迟低至140毫秒,适合实时交互场景,同时保证高质量音频输出。
4、稳定语音输出:在独白与对话测试中,生成语音与目标说话人相似度高,语音识别错误率低,能维持稳定的音质与韵律。
5、随机音色生成:可生成随机特征的语音,适用于构建语音识别模型训练数据或为语音交互系统提供多样化测试素材。
-

广告合作
-

QQ群号:4114653