无论是网站运营还是平台运营都会面临图片处理的难题,例如如何高效、准确的对海量酒店图片进行分类,有效提供平台的运营效率和和用户体验。接下来站长百科将主要介绍如何利用Amazon SageMaker部署LLaVA模型,从而实现酒店图片的自动化、高精度分类,以应对千万级别图片的处理需求,并降低运营成本。
当下问题:随着平台数据量的急剧增加,人工分类方法已经难以应对每天可能新增的数十万张图片,还容易出现分类不一致,因此需要一个自动化、高精度的图片分类解决方案。
具体目标:准确分类酒店图片,如房间、大堂、泳池、餐厅等几十余种;高效处理千万级别的存量图片,同时控制推理成本。
一、解决方案介绍
近些年多模态AI模型(能同时处理文本和图像的模型)已经发展的相当强大了,例如Claude3.5的多模态能力,能够直接用于图片分类任务。但是在大规模场景中使用这些模型仍存在一些局限性,例如:
- 模型在自定义标签分类场景精度有上限,需要大量提示词工程的工作;
- 模型升级可能导致已积累的提示词失效;
- 推理成本较高。
结合以上考虑因素,本文选择开源的LLaVA作为基础模型,并使用私域数据进行微调。同时采用vllm推理加速框架,进一步提升模型的吞吐量。
微调是一种将预训练模型适应特定任务的技术,能够在保持模型通用能力的同时,显著提升其在特定领域的表现。这种方法能够实现自主可控、性能达标且具有成本效益的图片处理模型;而vllm是一个高效的大语言模型推理引擎,能够显著提高模型的处理速度,这对于处理大规模图片数据集尤为重要。
二、LLaVA模型是什么
LLaVA全称为“Large Language and Vision Assistant”——强大的多模态AI模型,不仅结合了预训练的大语言模型(LLM),还采用了预训练的视觉编码器,同时理解和处理文本和图像信息,适用于诸如图像分类、图像描述等多模态任务。
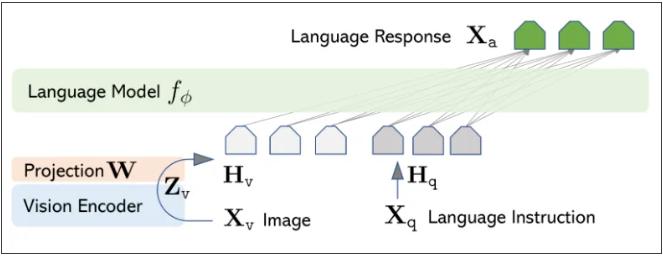
本文演示方案使用了LLaVa-NeXT(也称为LLaVa-1.6)——LLaVA的最新版本。相较于前代模型LLaVa-1.5,LLaVa-1.6通过以下改进显著提升了性能。
- 提高了输入图像分辨率,使模型能够捕捉更多图像细节;
- 在改进的视觉指令调优数据集上进行训练,增强了模型的理解能力;
- 显著提升了OCR(光学字符识别)能力,使模型更擅长识别图像中的文字;
- 增强了常识推理能力,使模型能够更好地理解图像内容的上下文。
本实例使用的具体版本是基于Mistral 7B的LLM:llava-hf/llava-v1.6-mistral-7b-hf。
注意:LLava系列适配多种LLM的语言头,这些模型在不同下游任务的表现各有优劣,具体可以参考各大榜单,进行最新的模型选择,在本方案的基础上快速切换。
三、数据准备
模型的性能离不开高质量的训练数据,因此需要精心准备训练数据集,具体步骤如下:
1、收集各类酒店场景的图片数据集:图片种类和数量尽可能丰富、尽量覆盖各种可能的场景,如不同类型的房间、各种风格的大堂、室内外泳池、各式餐厅等。
2、为每张图片标注相应类别:需要专业知识,确保标注的准确性和一致性。
3、构建图像——文本对:训练数据的核心。每个训练样本应包含一张图片和与之相关的问题——答案对。例如,问题可以是“这张图片展示的是什么类型的酒店设施?”,答案则是相应的类别。
4、为了高效管理这些训练数据,推荐使用Hugging Face的datasets包。该强大工具不仅可以帮助下载和使用开源数据集,还能高效地进行数据预处理。使用datasets可以将数据构造成如下格式。
from datasets import Dataset, DatasetDict, Image, load_dataset, load_from_disk
dataset = load_from_disk('data.hf')
dataset['train'][0]
{
'id': 133,
'images': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=550x412>,
'messages': [
{
'content': [
{
'index': None,
'text': 'Fill in the blank: this is a photo of a {}, you should select the appropriate categories from the provided labels: [Pool,Exterior,Bar...]',
'type': 'text'
},
{
'index': 0,
'text': None,
'type': 'image'
}
],
'role': 'user'
},
{
'content': [
{
'index': None,
'text': 'this is a photo of Room.',
'type': 'text'
}
],
'role': 'assistant'
}
]
}
注意:在构造训练数据集的content.text时,提示词的格式对下游任务具有很大影响。经过测试发现,使用接近于预训练clip的格式模版:this is a photo of {},能够提升下游任务的准确率~5%。
四、模型训练
数据准备完成后需要进行模型微调。本例使用TRL(Transformer Reinforcement Learning)训练框架进行模型微调,基于deepspeed进行分布式训练。
以下是关键的训练命令及其重要参数:
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \ examples/scripts/sft_vlm.py \ --dataset_name customer \ --model_name_or_path llava-hf/llava-v1.6-mistral-7b-hf \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 1 \ --output_dir sft-llava-1.6-7b-hf-customer2batch \ --bf16 \ --torch_dtype bfloat16 \ --gradient_checkpointing \ --num_train_epochs 20 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 100 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --per_device_eval_batch_size 8
关键参数说明:
- –dataset_name:指定使用的数据集;
- –model_name_or_path:基础模型路径;
- –save_steps:每100步存储一次模型checkpoint;
- –num_train_epochs:训练轮数,本例设置为20轮;
- –learning_rate:学习率,本例设置为2e-5;
- –per_device_train_batch_size:每个设备的训练批次大小,这里设为1,注意由于本例微调数据量较小,建议使用较小的batch size提升精度表现。
测试结果显示,在一台配备Nvidia H100 GPU的P5实例上,训练1000张图片大约需要10分钟完成训练。训练时间可能会根据具体的硬件配置和数据集大小有所变化。训练结束后请将checkpoint上传至AWS S3,为后续推理部署做准备。
五、部署推理
模型训练完成后需要将其部署为可用的推理端点,接下来由Amazon SageMaker托管。
Amazon SageMaker是亚马逊云科技(AWS)推出的完全托管服务,汇集了广泛采用的AWS机器学习 (ML) 和分析功能,能够统一访问你的所有数据,为分析和人工智能提供一体式体验。优势如下:
- 使用单一数据和人工智能开发环境,以加快协作和构建;
- 使用多种工具开发和扩展人工智能使用案例;
- 使用开放湖仓以统一所有数据,从而减少数据孤岛;
- 使用端到端数据和人工智能治理,以满足企业安全需求。
目前AWS为新用户推出了100+免费体验产品,其中包括Amazon SageMaker,免费资源如下:

推荐阅读:《亚马逊云科技账号注册流程》
本例采用了基于DJL(Deep Java Library)的推理框架,将微调后的LLaVA 1.6模型部署在g5.xlarge实例上。
1、准备serving.properties文件,该文件用于指定推理框架和微调模型的位置。
engine = Python
option.rolling_batch=vllm
option.tensor_parallel_degree = max
option.max_rolling_batch_size=64
option.model_loading_timeout = 600
option.max_model_len = 7200
option.model_id = {{s3url}}
为了提升推理速度,这里将vllm作为推理引擎。
2、将配置目录打包上传到Amazon S3,然后使用以下代码完成部署推理端点。
from sagemaker.model import Model model = Model( image_uri=inference_image_uri, model_data=s3_code_artifact, role=role, name=deploy_model_name, ) predictor = model.deploy( initial_instance_count=1, instance_type="ml.g5.xlarge", endpoint_name=endpoint_name )
以上代码Amazon SageMaker的Model类来创建和部署模型。指定模型镜像、模型数据位置、Amazon IAM角色等信息,然后调用deploy方法来创建推理端点。
3、部署完成后,可以测试推理端点。例如请求包含一个文本问题和一张base64编码的图片,模型将分析图片并回答问题。以下为测试示例,构造包含文本和图片的请求:
inputs = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Fill in the blank: this is a photo of a {}"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 256
}
output = predictor.predict(inputs)
{
'id': 'chatcmpl-140501937231984',
'object': 'chat.completion',
'created': 1732716397,
'choices': [{
'index': 0,
'message': {
'role': 'assistant',
'content': ' this is a photo of Terrace/Patio.'
},
'logprobs': None,
'finish_reason': 'eos_token'
}],
'usage': {
'prompt_tokens': 2168,
'completion_tokens': 12,
'total_tokens': 2180
}
}
在该示例中,模型识别出预定义的类别:Terrace/Patio。
六、成本估算
由于vllm批量推理的特性,每千张图片的推理时间约674秒,结合g5.xlarge的实例价格,千张图片的推理成本约为0.26美元。
相关推荐:
《亚马逊云科技Amazon EC2部署DeepSeek-R1蒸馏模型教程》
-

广告合作
-

QQ群号:4114653