RAG(检索增强生成)解决了传统大语言模型常因知识局限而产生“幻觉”,想要低成本高效实现RAG该如何操作呢?站长百科将在下文借助阿里云Milvus和低代码AI平台Dify,快速构建企业级检索增强生成(RAG)应用,提升AI应用的回答准确性与可靠性。
一、各平台简介
1、阿里云Milvus
阿里云官网:点击直达
阿里云向量检索服务Milvus版是一款全托管向量检索引擎,100%兼容开源Milvus,在性能、稳定性、可用性、管控能力等多个方向进行大量优化的云原生化向量检索引擎。在开源版版本的基础上增强了稳定性、可用性与可扩展性,能提供超大规模向量数据的相似性检索服务。
阿里云向量检索服务Milvus版基于Serverless的架构打造产品能力,提供快速的水平和垂直集群扩展能力;同时集成了丰富的Vector检索库,凭借其高性能、高可用性的特点,支持混合查询、聚合检索、多向量查询等高阶能力,为用户提供高效且稳定的向量数据检索能力。
阿里云向量检索服务Milvus版快速上手:
- 开通阿里云Milvus服务:打开阿里云Milvus开通页面,通过资源计算器大致评估所需的计算资源规模;
- 完成权限授权并导入数据:完成权限授权以及网络安全配置,通过SDK或Attu数据可视化组件导入数据;
- 进行向量检索:使用阿里云Milvus进行向量检索,检查Milvus实例监控、报警功能,并体验更多功能。
2、Dify
Dify是一个开源人工智能应用开发平台,常用来和n8n工作流平台作比较,具有低代码的工作流和友好的用户界面的特点,其核心使命是通过将“后端即服务”(Backend-as-a-Service)与“大语言模型运维”(LLMOps)的理念深度融合,来彻底简化和加速AI应用的构建全过程。
Dify是一个全栈式的解决方案,后端层面提供了稳定可靠的API服务、数据管理等基础设施,让开发者无需从零搭建;在 LLM 运维层面,提供了一个直观的可视化提示词编排界面,让复杂的提示工程变得简单高效。其内置的高质量检索增强生成(RAG)引擎,能够轻松连接企业文档、数据库等私有知识库,让大模型基于特定领域的知识进行回答,有效减少了信息幻觉,并确保答案的准确性和可追溯性。
二、RAG系统构建条件
基于本教程的RAG系统搭建指南需要确保已经创建阿里云Milvus实例,并且开通百炼服务并获得API-KEY。
获取APP ID和Workspace ID步骤如下:
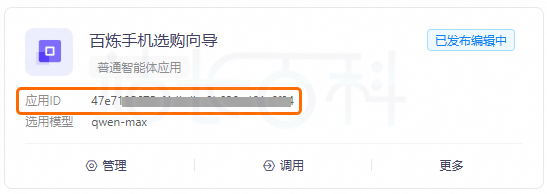
1、获取APP ID
APP ID即应用ID,通过接口调用阿里云百炼的应用(智能体、工作流或智能体编排)时,需要获取APP ID,并将代码示例中的YOUR_APP_ID替换为实际值。
前往应用管理页面,找到目标应用,您即可获取应用ID。
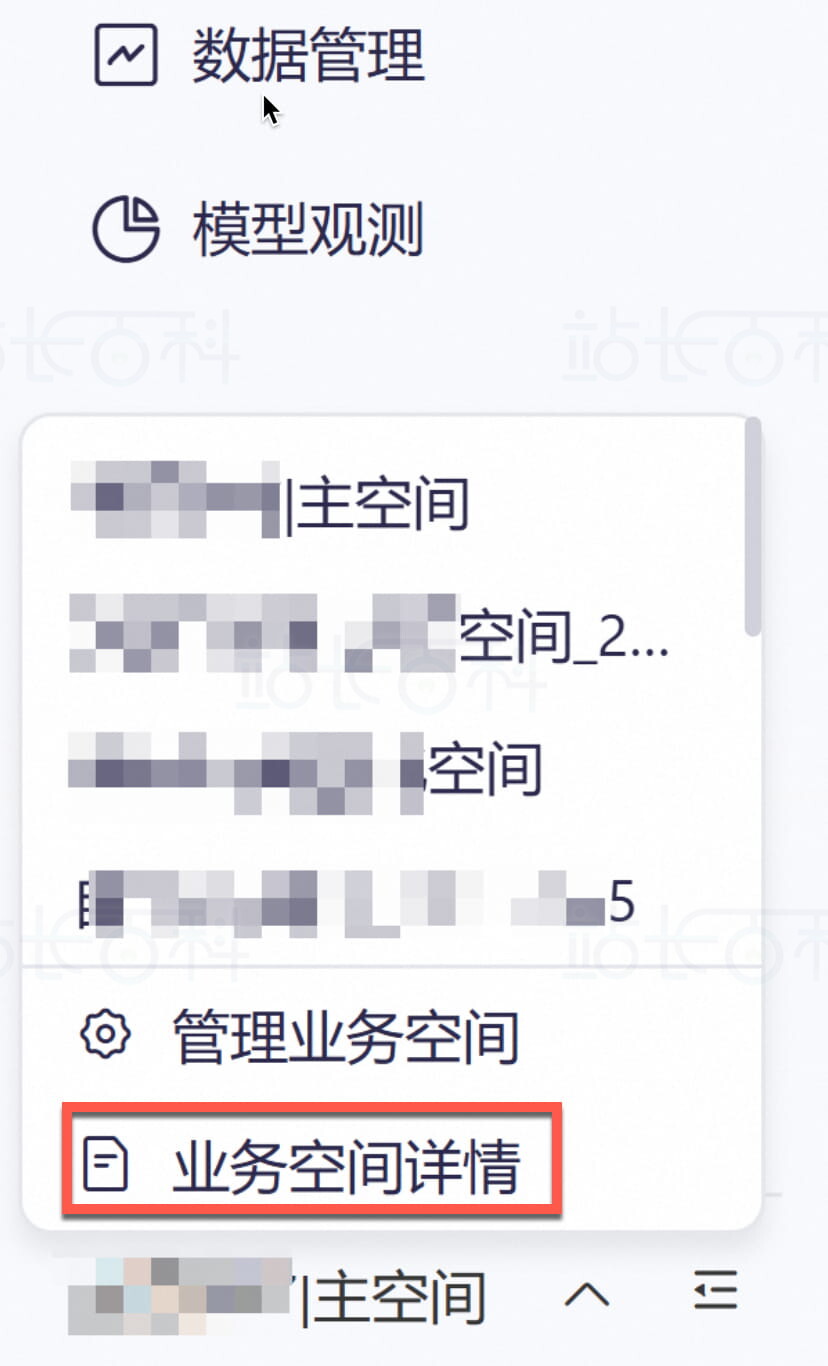
2、获取Workspace ID
Workspace ID即业务空间ID,是业务空间的唯一标识,一经生成即保持不变。示例:llm-7c72iiw36kd8****。通过API调用子业务空间下的应用时需要指定Workspace ID。调用默认业务空间下的应用时无需传递Workspace ID。
获取主账号下的所有业务空间ID:请前往业务空间管理界面获取。需主账号操作。如需使用子账号,请为您的子账号配置管控层权限(需AliyunBailianFullAccess或AliyunBailianControlFullAccess),否则访问页面会报错。
获取当前业务空间ID:请前往阿里云百炼控制台首页,然后单击界面左下角的小箭头图标,再单击业务空间详情获取。默认情况下,子账号只能查看已加入的子业务空间的ID。
以上不支持通过API或命令行操作。
三、阿里云Milvus和Dify平台构建RAG系统教程
1、安装与配置Dify
在开始之前,请确保本地Git、Docker、Docker-Compose安装完毕。
将dify项目通过git命令clone到本地
git clone https://github.com/langgenius/dify.git
进入目录备份.env配置文件
cd dify
cd docker
cp .env.example .env
修改配置文件.env
VECTOR_STORE=milvus
MILVUS_URI=http://YOUR_ALIYUN_MILVUS_ENDPOINT:19530
MILVUS_USER=YOUR_ALIYUN_MILVUS_USER
MILVUS_PASSWORD=YOUR_ALIYUN_MILVUS_PASSWORD
注意:用Aliyun Milvus的公网地址替换YOUR_ALIYUN_MILVUS_ENDPOINT;用Aliyun Milvus的用户名替换YOUR_ALIYUN_MILVUS_USER;用Aliyun Milvus的密码替换YOUR_ALIYUN_MILVUS_PASSWORD。
通过docker compose命令启动
docker compose up -d
安装成功验证
启动后访问http://127.0.0.1/ 进入dify的登陆页面,设置管理员账号密码,并登陆进管控台。
2、设置默认模型
在设置–模型提供商处安装模型供应商,在这里我们选用了通义千问的模型,可以将在百炼平台获取API-KEY 输入,验证绿灯即可。
系统模型设置:将通义千问对应的模型设置到每种模型处。
3、准备数据集创建知识库
接下来准备测试数据来创建知识库。
在选择数据源处选择“导入已有文本”,可使用milvus官网的中文README作为测试数据源文件
https://github.com/milvus-io/milvus/blob/master/README_CN.md
参考如下配置进行数据源的处理与保存,创建知识库。
可以看到数据库已经成功创建,并且索引创建完毕。
4、验证向量检索是否成功
通过docker logs 查看,可以看到dify日志里显示上传成功;
访问集群Attu Manager控制台,可以看到对应的collection 数据已导入。
5、验证RAG效果
- 在应用模板中创建一个knowledge retreival + chatbot作为基础模板;
- 修改knowledge retreival节点,设置前步骤的知识库;
- 修改chatbot节点,设置语言大模型,这里使用qwen-max大模型;
- 设置好后点击发布,然后点运行进入测试界面;
- 这里输入一个与知识库中内容相关的问题,可以得到答案。
如果想体验阿里云Milvus的相关能力,可以在阿里云官网搜索向量检索服务Milvus版进行体验。产品新用户也可免费领取1个月试用资格。此外阿里云为了回馈新老用户,推出了重大优惠:
阿里云向量检索服务Milvus版 限时年付5折!购买地址
-

广告合作
-

QQ群号:4114653