

类型:向量数据库
简介:存储、索引和管理由深度神经网络和机器学习(ML)模型生成的大规模嵌入向量。
Milvus广泛用于处理高维向量数据,适用于需要高效搜索和存储海量向量的应用场景。它支持多种向量类型的存储和检索,特别适用于推荐系统、图像搜索、自然语言处理等领域。本文将概述如何使用Milvus进行数据库、集合、分区的管理,以及如何插入、更新、删除数据、执行向量搜索等操作。
一、管理数据库
与传统的数据库引擎类似,你可以在 Milvus 中创建数据库,并分配权限给特定的用户来管理它们。然后这些用户就有权利管理数据库中的集合。一个 Milvus 集群支持最多 64 个数据库。
1、创建数据库
要创建一个数据库,你需要先连接到一个 Milvus 集群,并为它准备一个名称:
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("book")
2、使用数据库
Milvus 集群附带一个名为 “default” 的默认数据库。除非另有指定,否则集合将在默认数据库中创建。
要更改默认数据库,请执行以下操作:
db.using_database("book")
也可以在连接到 Milvus 集群时设置要使用的数据库:
conn = connections.connect( host="127.0.0.1", port="19530", db_name="default" )
3、列出数据库
要查找 Milvus 集群中所有现有的数据库,请执行以下操作:
db.list_database()
4、删除数据库
要删除数据库,你必须首先删除它的所有集合。否则,删除操作将失败。
db.drop_database("book")
db.list_database()
5、使用数据库的RBAC
RBAC 也包括数据库操作并确保向前兼容性。Permission API(Grant / Revoke / List Grant)中的 database 一词具有以下含义:
- 如果既没有 Milvus 连接也没有 Permission API 调用指定db_name,则 database 指的是默认数据库;
- 如果 Milvus 连接指定了 db_name,但 Permission API 调用之后没有指定,则 database指的是在 Milvus 连接中指定名称的数据库;
- 如果 Permission API 调用在 Milvus 连接上进行,无论是否指定了 db_name,database都指的是在 Permission API 调用中指定名称的数据库。

如果既没有 Milvus 连接也没有 Permission API 调用指定 db_name,则database 指的是默认数据库。

如果 Milvus 连接指定了 db_name,但 Permission API 调用之后没有指定,则 database指的是在 Milvus 连接中指定名称的数据库。

如果 Permission API 调用在 Milvus 连接上进行,无论是否指定了 db_name,database都指的是在 Permission API 调用中指定名称的数据库。
二、管理集合
确保已经安装了所需的 SDK。你可以选择多种语言,包括 Python、Java、Go 和 Node.js。
在 Milvus 中,你可以将向量嵌入存储在集合中。集合中的所有向量嵌入共享相同的维度和用于衡量相似性的距离度量。Milvus 集合支持动态字段(即模式中未预定义的字段)和主键的自动递增。
为了适应不同的偏好,Milvus 提供了两种创建集合的方法。一种提供快速设置,而另一种允许详细定制集合的模式和索引参数。此外可以在需要时查看、加载、释放和删除集合。
1、创建集合
你可以通过以下两种方式之一创建集合:
(1)快速设置
在此方式中,你可以通过仅提供名称和要存储在该集合中的向量嵌入的维度数量来创建集合。
(2)自定义设置
你可以根据自己的需求确定集合的 模式 和 索引参数,而不是让 Milvus 为集合几乎决定一切。
2、快速设置
在人工智能领域取得巨大进展的背景下,大多数开发人员只需要一个简单而动态的集合即可开始。Milvus 允许使用仅三个参数快速设置此类集合:
- 要创建的集合名称;
- 要插入的向量嵌入的维度;
- 用于衡量向量嵌入之间相似性的度量类型。
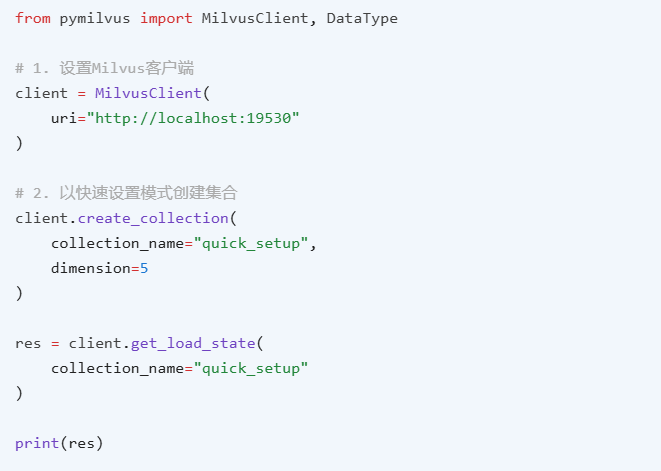
上述代码中生成的集合仅包含两个字段:id(作为主键)和 vector(作为向量字段),默认启用了 auto_id 和 enable_dynamic_field 设置。
auto_id
启用此设置可确保主键自动递增。在数据插入过程中无需手动提供主键。
enable_dynamic_field
启用后,将把要插入的数据中除 id 和 vector 之外的所有字段视为动态字段。这些额外的字段将保存在一个名为 $meta 的特殊字段中,以键值对的形式存储。这个功能允许在数据插入过程中包含额外的字段。
提供的代码自动生成的、具有自动索引和加载状态的集合已准备好进行数据插入。
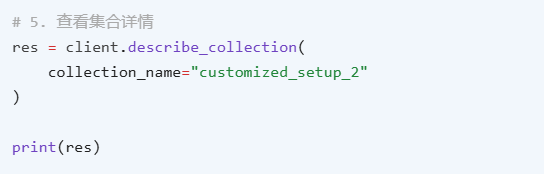
3、查看集合
可以按如下方式查看现有收藏的详细信息:
要列出所有现有的集合,可以按如下方式操作:

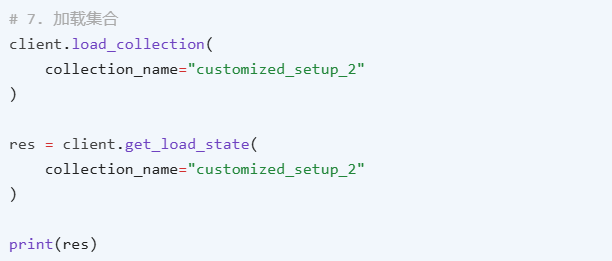
4、加载释放集合
在加载集合过程中,Milvus 会将集合的索引文件加载到内存中。相反,在释放集合时,Milvus 会从内存中卸载索引文件。在进行集合搜索之前,请确保集合已加载。
加载集合:
5、删除集合
如果不再需要某个集合,可以删除该集合。

三、管理分区
你可以向集合中添加更多的分区。一个集合最多可以有 64 个分区。
1、检查特定分区
你还可以检查特定分区是否存在。

上述代码片段检查了集合是否存在名为 partitionA 和 partitionC 的分区。
2、加载和释放分区
你可以加载和释放特定的分区,使它们可用或不可用于搜索和查询。
(1)加载分区
加载集合的所有分区,只需调用 load_collection()。要加载集合的特定分区,请按以下步骤操作:
要同时加载多个分区,请按如下方式操作:

(2)释放分区
要释放集合的所有分区,只需调用 release_collection。要释放集合的特定分区,请按以下步骤操作:

要同时释放多个分区,请按如下方式操作:
(3)删除分区
一旦释放分区,如果不再需要,就可以删除它。
四、插入、更新和删除数据
在 Milvus 集合的上下文中,实体是集合中的一个单独的、可识别的实例。它代表着一个特定类别的独特成员,可以是图书馆中的一本书,基因组中的一个基因,或者任何其他可识别的实体。
集合中的实体共享一组通用的属性,称为 schema,用于描述每个实体必须遵循的结构,包括字段名称、数据类型和任何其他约束。
成功将实体插入到集合中需要提供的数据应包含目标集合的所有 schema 定义的字段。另外,如果你启用了动态字段,还可以包含非 schema 定义的字段。
1、准备工作
下面的代码片段重用了现有代码,用于与 Milvus 集群建立连接并快速设置一个集合。

2、插入实体
要插入实体,你需要将数据组织为一个字典列表,其中每个字典表示一个实体。每个字典都包含与目标集合中的预定义和动态字段相对应的键。

3、插入分区
要将数据插入到特定分区中,你可以在插入请求中指定分区的名称,示例如下:

4、更新实体
Upserting data(更新插入数据)是 update(更新)和 insert(插入)操作的组合。在 Milvus 中,upsert 操作根据实体的主键在集合中是否已存在来执行数据级操作,具体如下:
如果实体的主键已经存在于集合中,则会覆盖现有实体。
如果主键在集合中不存在,则会插入一个新实体。
5、删除实体
如果不再需要某个实体,可以将其从集合中删除。Milvus 提供了两种方法来识别要删除的实体
以下代码片段演示了如何从特定分区中按 ID 删除实体。如果未指定分区名称,它也可以正常工作。

五、单向量搜索
一旦你插入了数据,下一步就是在 Milvus 的集合中执行相似性搜索。
Milvus 允许你根据集合中的向量字段数量执行两种类型的搜索:
1、单向量搜索:如果你的集合只有一个向量字段,请使用 search()(opens in a new tab) 方法来查找最相似的实体。该方法将你的查询向量与集合中现有的向量进行比较,并返回最接近的匹配项的 ID 以及它们之间的距离。可选地,它还可以返回结果的向量值和元数据。
2、多向量搜索:对于具有两个或更多向量字段的集合,请使用 hybrid_search()(opens in a new tab) 方法。该方法执行多个近似最近邻(ANN)搜索请求,并将结果合并以返回重新排列后的最相关匹配项。
六、多向量搜索
自 Milvus 2.4 版本以来引入了多向量支持和混合搜索框架,用户可以将多个向量字段(最多 10 个)引入单个集合中。不同的向量字段可以表示不同的方面、不同的嵌入模型甚至是表征同一实体的不同的数据形态,这极大地扩展了信息的丰富性。这个特性在综合搜索场景中特别有用,比如基于各种属性(如图片、声音、指纹等)在向量库中识别最相似的人。
多向量搜索可以对多个向量字段执行搜索请求,并使用重新排序策略(如 Reciprocal Rank Fusion (RRF)和 Weighted Scoring)合并结果。















