类型:向量数据库
简介:存储、索引和管理由深度神经网络和机器学习(ML)模型生成的大规模嵌入向量。
Milvus是一个高效的向量数据库,广泛应用于处理大规模的向量数据,支持高性能的相似性搜索、向量检索等功能。本文将为你介绍如何在 Linux 系统中通过 Docker 部署 Milvus 向量数据库,并配置相关组件。
一、安装Docker
首先确保系统已经安装了 Docker。如果还没有安装,可以参考相关教程,如 Linux 系统 Docker 安装。
二、安装fio命令
在进行性能测试之前,我们需要先安装 fio 工具。通过以下命令可以安装:
yum install -y fio
三、进行磁盘性能测试
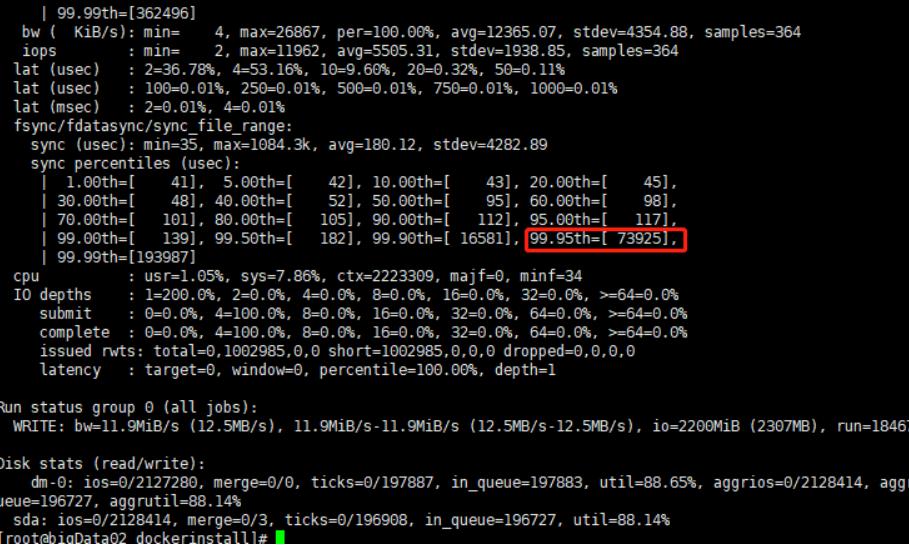
使用 fio 工具测试磁盘性能,运行以下命令来测试磁盘的读写性能:
fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=2200m --bs=2300 --name=mytest

四、检查CPU支持的指令集
为了确保 Milvus 正常运行,我们需要检查系统是否支持必要的 CPU 指令集。可以通过以下命令查看:
lscpu

在 “Flags” 字段中,你可以看到当前 CPU 支持的指令集。
五、检查Docker版本
根据 Milvus 安装要求,Docker 版本需要大于等于 19.03。你可以通过以下命令检查当前安装的 Docker 版本:
docker --version
确保版本大于或等于 19.03。如果你的版本符合要求,那么可以继续进行下一步。
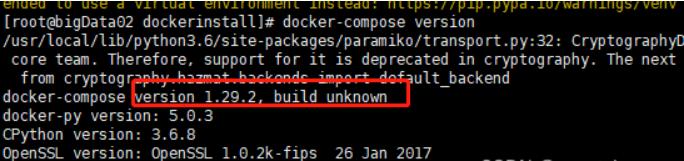
六、安装Docker Compose
Milvus 安装要求 Docker Compose 版本不低于 1.25.1。你可以通过以下命令安装 Docker Compose:
yum -y install python3-pip pip3 install --upgrade pip pip install docker-compose
七、下载Milvus脚本
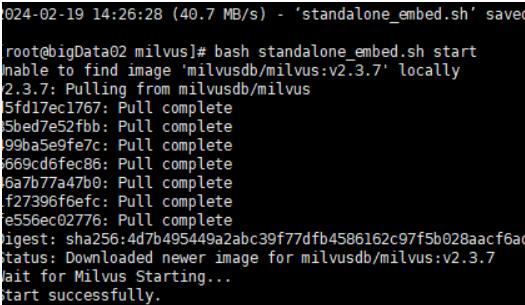
下载 Milvus 的部署脚本 “standalone_embed.sh”,可以通过以下命令完成:
wget https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh
八、启动Milvus
使用以下命令启动 Milvus 向量数据库:
bash standalone_embed.sh start
九、停止Milvus
如果需要停止 Milvus,可以使用以下命令:
bash standalone_embed.sh stop
十、删除数据
停止 Milvus 后,如果你想删除相关的数据,可以执行以下命令:
bash standalone_embed.sh delete
十一、运行Milvus
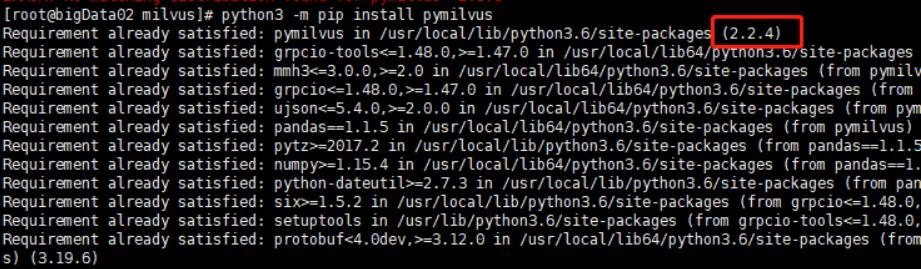
为了使用 Python 操作 Milvus,需要安装 PyMilvus 库。你可以通过以下命令安装:
python3 -m pip install pymilvus==2.3.6


如果需要安装最新版本的 PyMilvus,可以使用:
python3 -m pip install pymilvus
验证安装是否成功,可以运行以下 Python 代码:
python3 -c "from pymilvus import Collection"
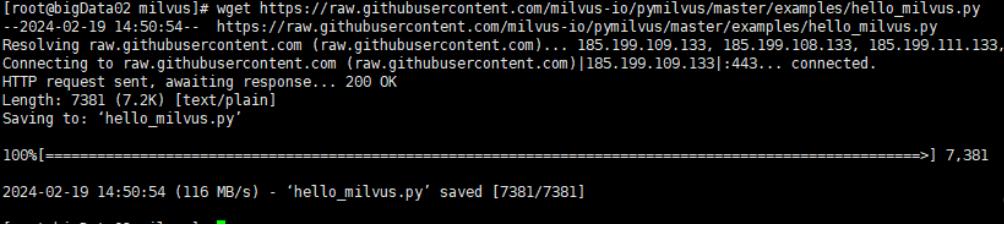
下载并运行 Milvus 示例代码:
十二、查看 Docker 容器状态
使用以下命令查看 Milvus 容器的运行状态:
docker ps

通过浏览器访问 Milvus 的健康检查接口,确认 Milvus 数据库服务器是否正常运行:
http://ip:9091/api/v1/health
如果返回结果为 “{“status”:“ok”}”,说明 Milvus 已经正常运行。
十三、查看Docker端口映射
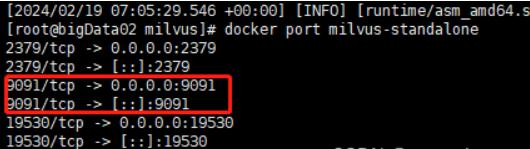
可以通过以下命令查看 Milvus 容器的端口映射情况:
docker port milvus-standalone
十四、安装Attu
最后,安装 Attu(一个基于 Milvus 的向量可视化管理工具)。使用以下命令启动 Attu:
docker run -p 8000:3000 -e MILVUS_URL=192.168.1.242:19530 zilliz/attu:latest

通过浏览器访问 http://ip:8000,即可使用 Attu 管理界面。