类型:向量数据库
简介:存储、索引和管理由深度神经网络和机器学习(ML)模型生成的大规模嵌入向量。
为应对用户需求的多样性,Milvus提供了更为丰富的迁移工具,支持从Milvus 1.x版本的升级,同时也能轻松将数据从Elasticsearch、Faiss 等系统迁移至 Milvus。解决不同数据环境与 Milvus 技术最新进展之间的差异,帮助用户平滑过渡并充分利用 Milvus 在向量搜索领域的优势。
一、Milvus支持的迁移路径
Milvus-migration 工具为用户提供了多种迁移选项,支持不同的迁移需求:
1、从 Elasticsearch 迁移到 Milvus 2.x:使用户能够将 Elasticsearch 环境中的数据迁移到 Milvus,享受后者优化的向量搜索功能。
2、从 Faiss 迁移到 Milvus 2.x:为从 Faiss(一个广泛使用的相似性搜索库)迁移数据的实验性支持。
3、从 Milvus 1.x 到 Milvus 2.x:确保早期版本中的数据能够平稳迁移至最新版本。
4、从 Milvus 2.3.x 到更高版本:为已迁移至 Milvus 2.3.x 的用户提供无缝升级路径。
二、Milvus-migration工具的特点
Milvus-migration 提供了一些独特的功能,使其能够高效地处理各种迁移需求:
1、多种交互方式:支持通过命令行界面(CLI)或 RESTful API 进行迁移,用户可以根据需求灵活选择操作方式。
2、支持多种存储方案:Milvus 迁移工具能够处理存储在本地文件或云存储(如 S3、OSS、GCP 等)中的数据,确保兼容性。
3、数据类型处理:该工具不仅支持向量数据,还能处理标量字段,适应多样化的数据迁移需求。
三、Milvus-migration架构
Milvus-migration 的架构经过精心设计,旨在确保数据流、解析和写入过程的高效性。通过简化的数据访问和读取流程,它能够从多个数据源提取信息并启动迁移工作。
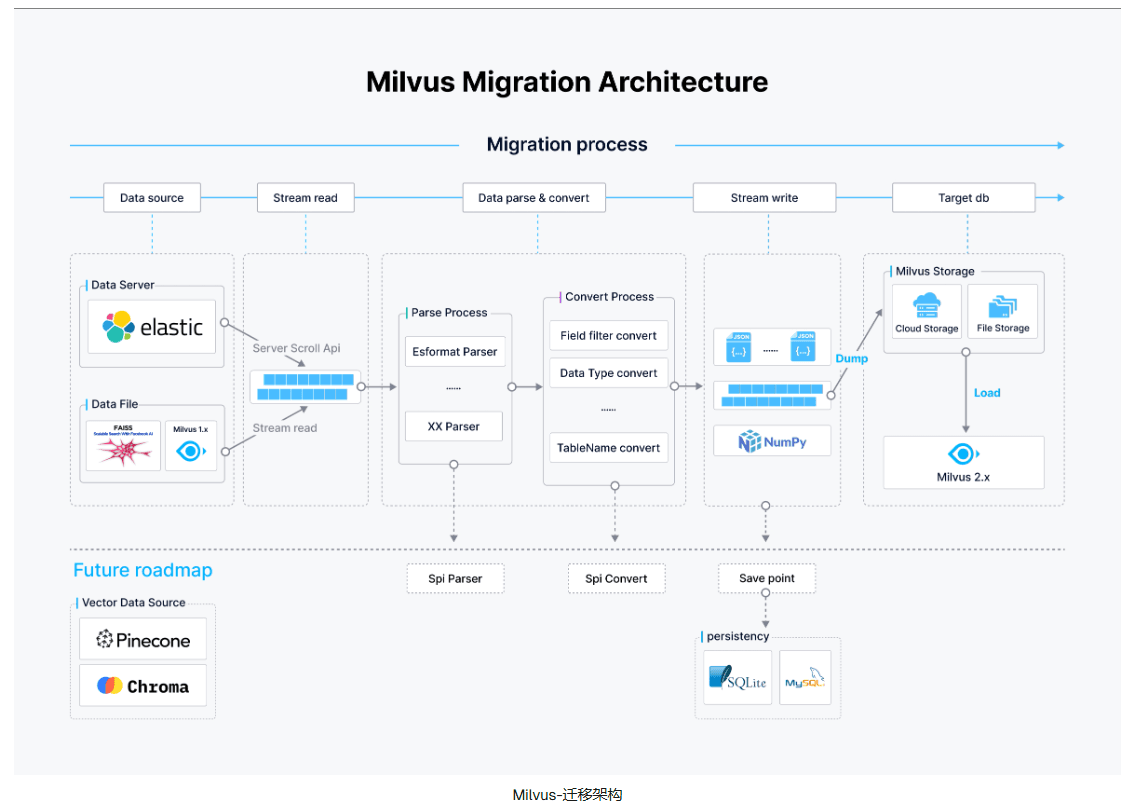
1、数据源支持:支持多种数据源,如通过 scroll API 访问的 Elasticsearch、本地或云存储的数据文件,甚至 Milvus 1.x 数据库。它将以高效简洁的方式读取这些数据。
2、迁移流水线:
(1)解析过程:数据根据其格式进行解析。例如,对于 Elasticsearch 数据,工具会使用 Elasticsearch 格式解析器,其他格式则使用相应的解析器。这一步骤至关重要,因为它将原始数据转化为便于进一步处理的结构化数据。
(2)转换过程:解析后的数据需要进行格式转换,确保字段过滤、数据类型转换及表名调整符合目标 Milvus 2.x 的要求。
3、数据写入和加载:
(1)写入数据:将处理过的数据写入 JSON 或 NumPy 文件,以便进一步加载。
(2)加载数据:使用 BulkInsert 操作将处理过的数据批量写入 Milvus,确保数据高效导入。
四、安装Milvus-migration工具
用户可以选择两种方式来安装 Milvus-migration 工具:下载预编译的二进制文件或从源代码进行编译。
1、下载二进制文件:
- 访问 Milvus-Migration GitHub 仓库下载最新版本的二进制文件;
- 解压文件,获取 milvus-migration 可执行文件。
2、从源代码编译:
克隆 Milvus-Migration 仓库:
git clone https://github.com/zilliztech/milvus-migration.git
导航到项目目录:
cd milvus-migration
使用 Go 编译项目,生成可执行文件:
go get && go build
这将在项目目录中生成 milvus-migration 可执行文件。
五、Elasticsearch向Milvus 2.x迁移
1、前提条件
- 源 Elasticsearch:7.x 或 8.x
- 目标 Milvus:2.x
- 所需工具:Milvus-migration 工具
- 支持的迁移数据类型:dense_vector、keyword、text、long、integer、double、float、boolean 和 object 等数据类型,其他类型目前不支持迁移。
2、配置迁移文件
将示例迁移配置文件保存为 migration.yaml,并根据实际情况修改配置文件。配置文件可以放在任意本地目录下。
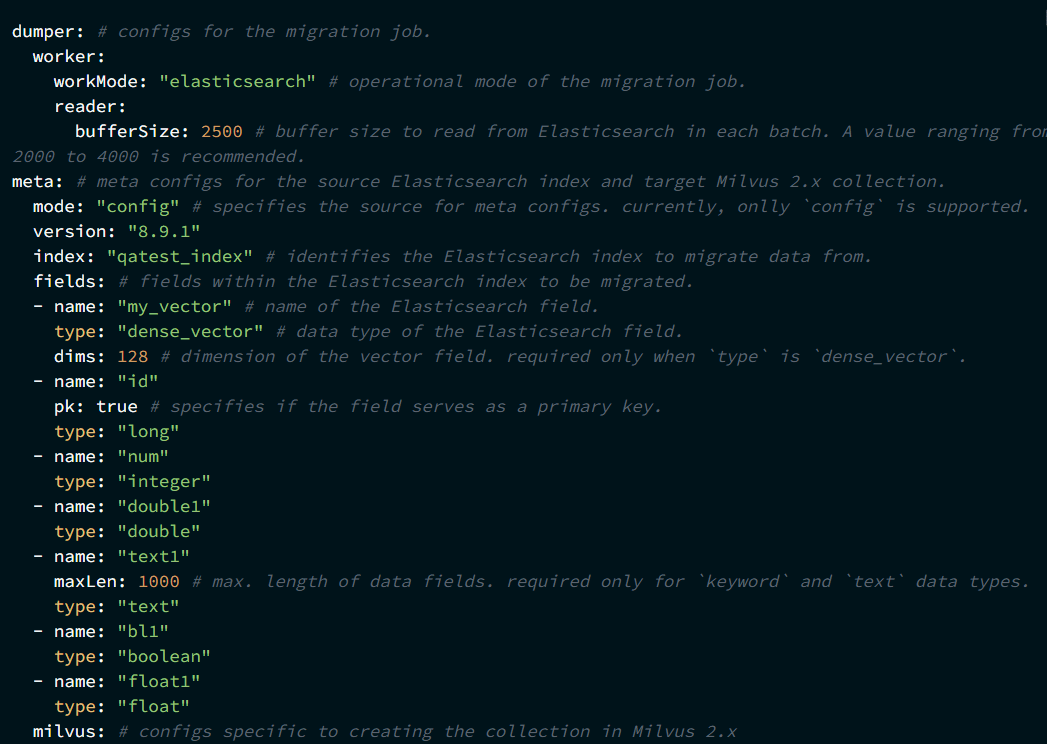
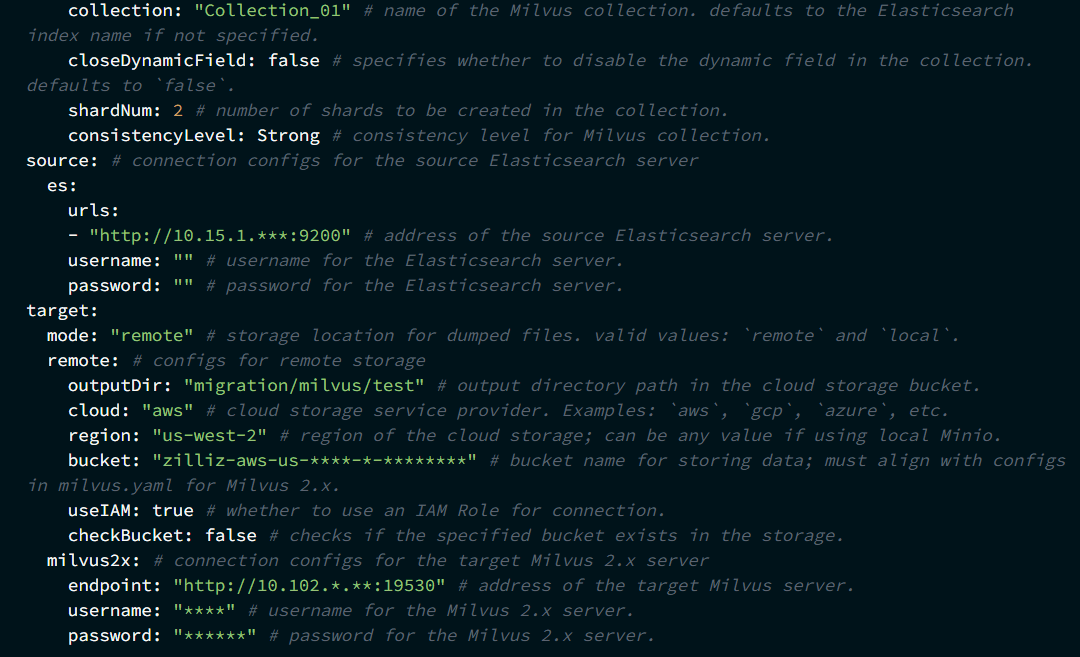
2、启动迁移任务
执行以下命令启动迁移任务,并将 {YourConfigFilePath} 替换为实际配置文件的路径:
./milvus-migration start --config=/{YourConfigFilePath}/migration.yaml
如果迁移成功,日志中将显示迁移完成的相关信息。
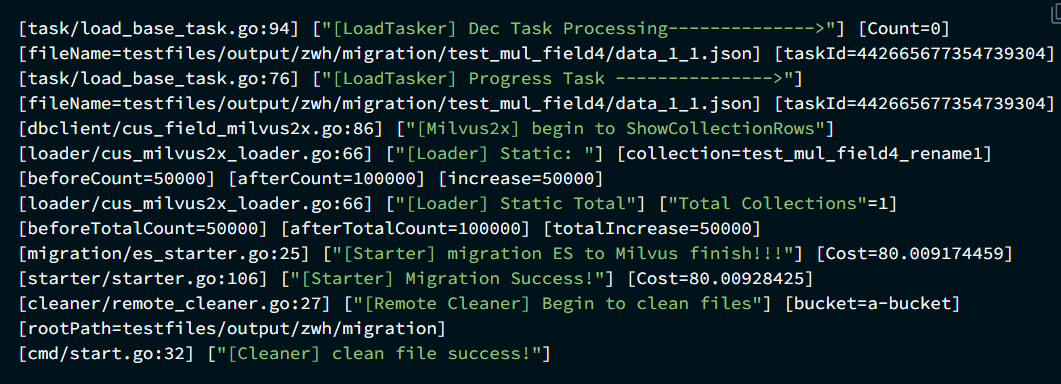
3、验证迁移结果
迁移完成后,可以通过 API 或使用 Attu 工具来验证已迁移数据的数量,确保迁移过程顺利进行。
六、从Faiss向Milvus 2.x迁移
1、前提条件
- 源 Faiss:任何版本的 Faiss
- 目标 Milvus:2.x
- 所需工具:Milvus-migration 工具
2、配置迁移
与 Elasticsearch 迁移类似,首先保存并修改迁移配置文件 migration.yaml。然后,按照需求执行迁移任务。
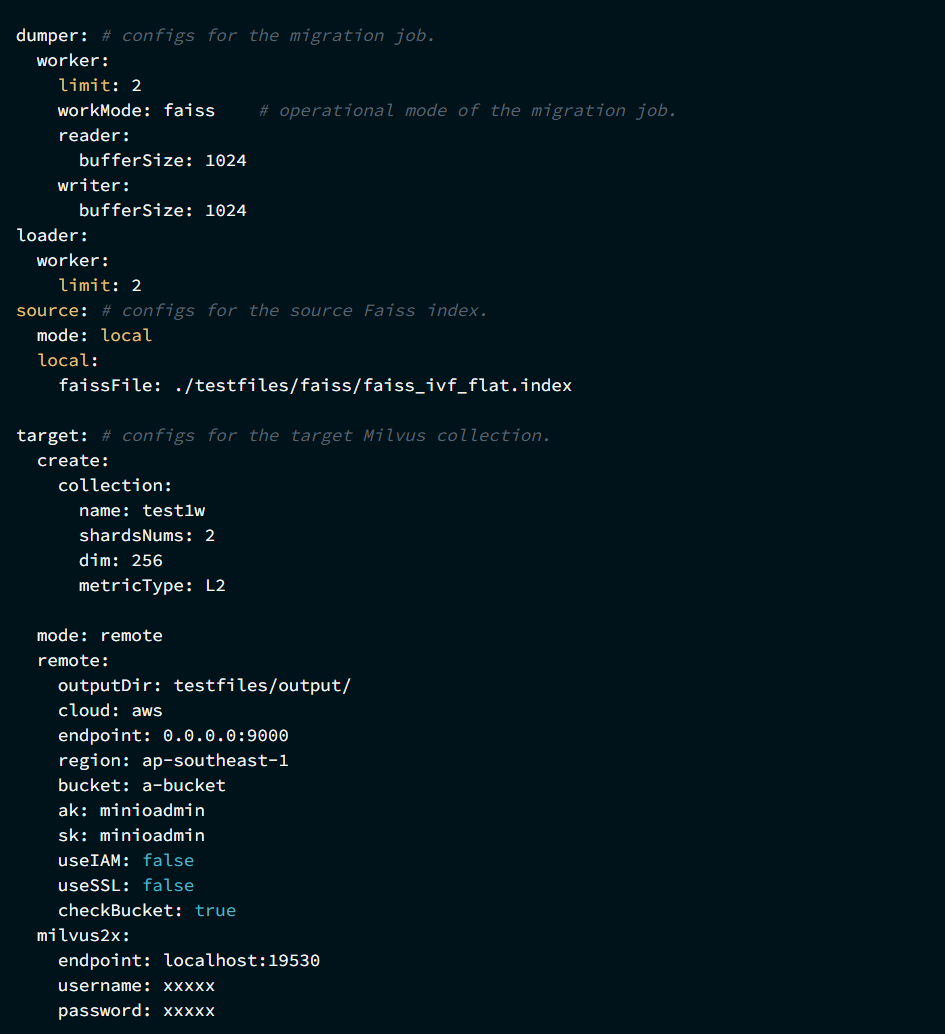
(1)导出源数据:使用 ./milvus-migration dump 命令将源数据导出为 NumPy 文件。
(2)加载目标数据:使用 ./milvus-migration load 命令将 NumPy 文件导入到目标 Milvus 2.x。
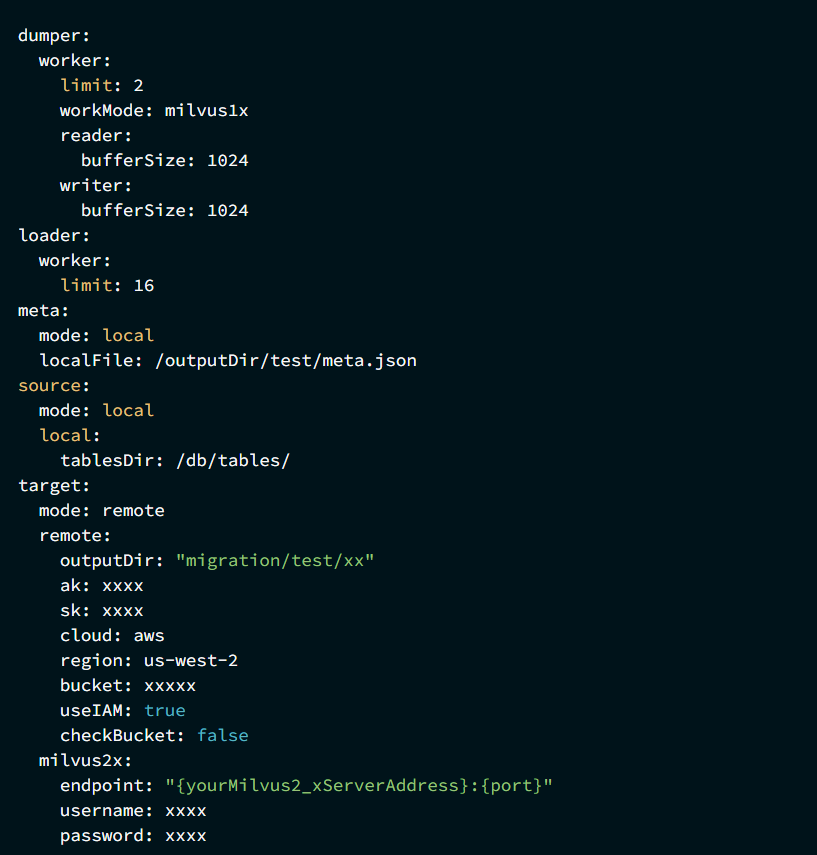
七、从Milvus 1.x(包括0.9.x及以上版本)向Milvus 2.x迁移
1、准备工作: 确保 Milvus 1.x 环境停止所有 DML 操作,并导出源数据。
2、启动迁移任务

如果使用 MySQL,执行:
./milvus-migration export -s /milvus/db/meta.sqlite -o outputDir
如果使用 SQLite,执行:
./milvus-migration export -s /milvus/db/meta.sqlite -o outputDir
迁移配置:保存并修改 migration.yaml 配置文件,根据源和目标环境的实际路径。
3、执行迁移任务
启动数据迁移命令:
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml

导入 NumPy 文件到 Milvus 2.x:
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
八、从Milvus 2.x版本(如2.3.x)向更高版本迁移
1、准备工作
- 确保源 Milvus 版本为 2.3.x 或更高,目标版本为 2.3.x 或更高;
- 数据准备好并已加载,迁移后需手动索引目标数据。
2、执行迁移任务:
使用命令启动迁移:
./milvus-migration start --config=/{YourConfigFilePath}/migration.yaml
3、验证结果:
迁移完成后可以通过以下方式验证:
- 使用 Attu 查看已迁移的实体数量;
- 调用 API 以确认数据已成功迁移。
注意事项:
- 在迁移过程中,确保配置文件路径正确且所有必要的依赖项已安装;
- 目标 Milvus 版本需要手动创建索引,迁移后不会自动编入索引;
- 迁移期间可能需要监控日志输出,确保无错误发生。