
Apache Hadoop作为分布式计算的技术基石,已成为企业构建大数据平台的核心选择。对于大数据运维工程师而言,需要深入理解Hadoop的底层架构。站长百科本篇文章将从实战角度出发,系统讲解Hadoop组件原理、部署配置、性能调优及故障处理。
一、Hadoop起源
Hadoop的起源可追溯至Google在2003-2004年发布的两篇里程碑式论文——《The Google File System》与《MapReduce: Simplified Data Processing on Large Clusters》。这两篇论文提出的分布式存储与计算思想,为大数据处理奠定了理论基础。
2005年,Apache Nutch项目负责人Doug Cutting团队基于上述论文思想,开发了分布式文件系统与计算框架,并以其儿子的玩具大象命名为”Hadoop”。2008年Hadoop成为Apache顶级项目,随后逐步构建起庞大的开源生态。
Hadoop版本从1.x到3.x的技术突破:
1、Hadoop 1.x(2006-2012)
核心组件为HDFS(分布式文件系统)与MapReduce(计算框架),采用JobTracker/TaskTracker架构。但JobTracker单点故障风险、资源利用率低(CPU/内存分配僵化)、扩展性受限(集群规模难以突破4000节点)。
2、Hadoop 2.x(2012-2017)
引入YARN资源管理框架,实现资源管理与作业调度分离,引入ResourceManager/NodeManager架构,资源管理与作业调度分离、支持多种计算框架。
3、Hadoop 3.x(2017至今)
Hadoop 3.x采用纠删码(Erasure Coding)替代副本机制,引入Timeline Service V2优化作业追踪;支持GPU/FPGA硬件加速与容器化部署,逐步实现云原生适配(如Kubernetes集成)。
Hadoop生产环境版本选择建议:
- 生产环境推荐:Hadoop 3.1.x/3.2.x
- 新项目建议:Hadoop 3.3.x
- 保守选择:Hadoop 2.10.x
二、Hadoop核心架构深度剖析
Apache Hadoop生态采用主从(Master-Slave)架构设计,核心组件包括:
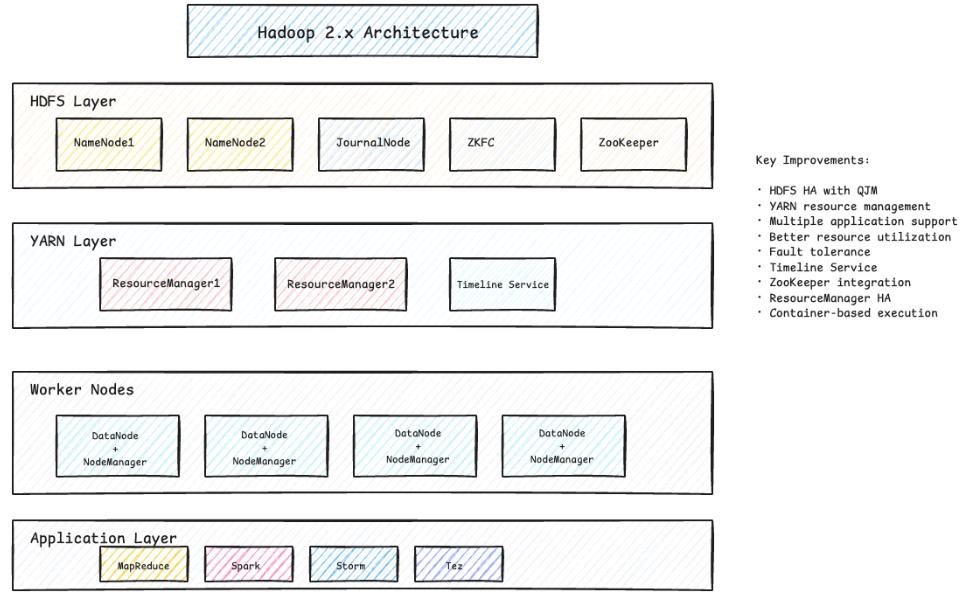
1、HDFS(Hadoop Distributed File System):Hadoop的分布式存储核心
HDFS是专为大规模数据存储设计的分布式文件系统,采用一写多读模型。核心组件:
- NameNode(名称节点):存储文件系统元数据,管理数据块分布;
- DataNode(数据节点):存储实际数据块,执行读写操作;
- Secondary NameNode:存储实际数据块,执行读写操作。
工作流程:
写入流程:客户端向NameNode请求写入文件,NameNode返回可用DataNode列表;客户端将文件切分为数据块,通过Pipeline机制向第一个DataNode写入;数据块在DataNode间自动复制。
读取流程:客户端向NameNode查询文件块位置,NameNode返回距离最近的DataNode列表;客户端直接从DataNode读取数据块。
2、YARN(Hadoop Distributed File System):资源管理框架
YARN是Hadoop2.x引入的资源管理系统,核心组件如下:
- ResourceManager:集群资源总调度者;
- NodeManager:单节点资源管理和容器监控;
- ApplicationMaster:单个应用程序的资源协调者;
- Container:资源抽象,封装CPU、内存等资源。
作业执行流程:Client → ResourceManager → NodeManager → ApplicationMaster → Container
三、单点Hadoop集群部署实战
1、环境准备清单
- CPU≥8核
- 内存≥16GB
- 磁盘≥500GB(建议选择SSD)
- 千兆网卡
- CentOS 7.x / Ubuntu 18.04+操作系统
- OpenJDK 8或Oracle JDK 8
- SSH免密登录配置
2、系统环境预配置
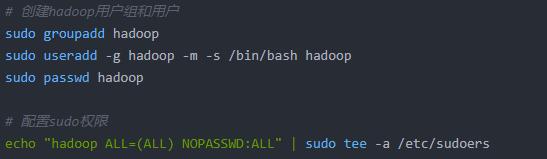
(1)Hadoop用户和用户组创建
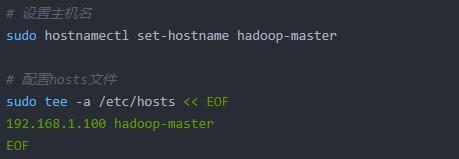
(2)设置配置主机名与hosts
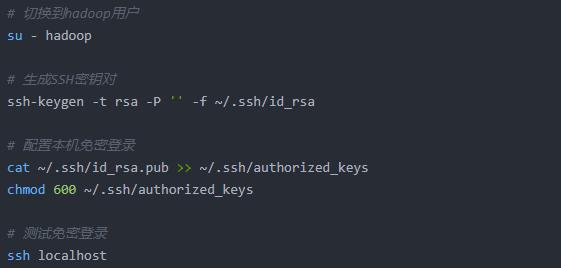
(3)配置SSH免密登录
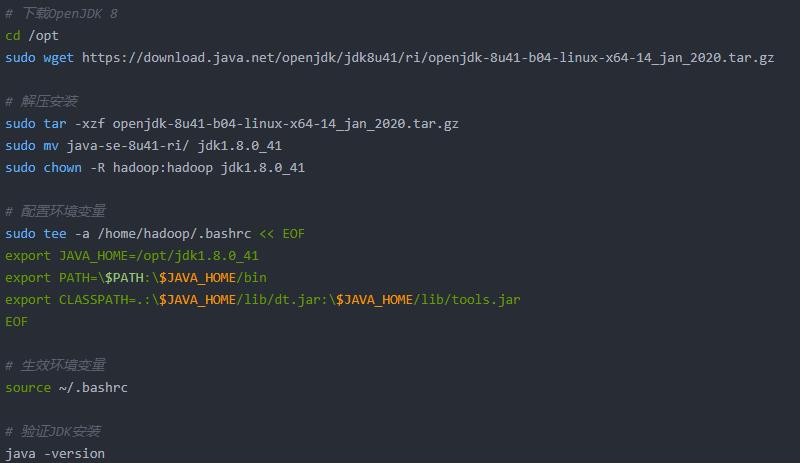
(4)安装JDK并配置环境变量
3、Hadoop安装与核心配置
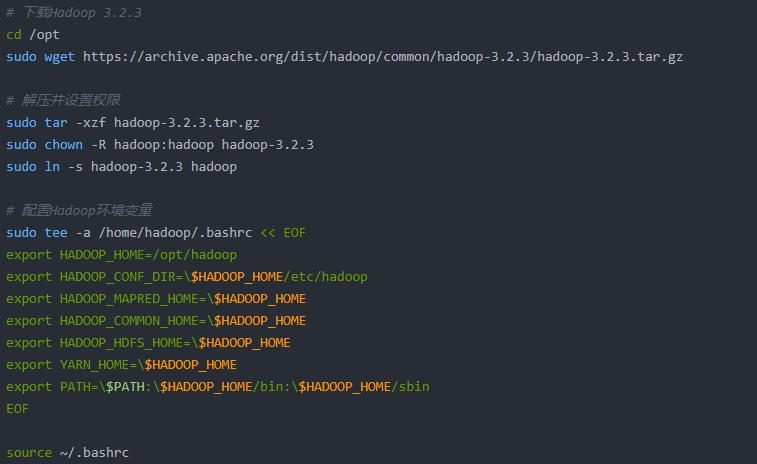
(1)下载并解压Hadoop
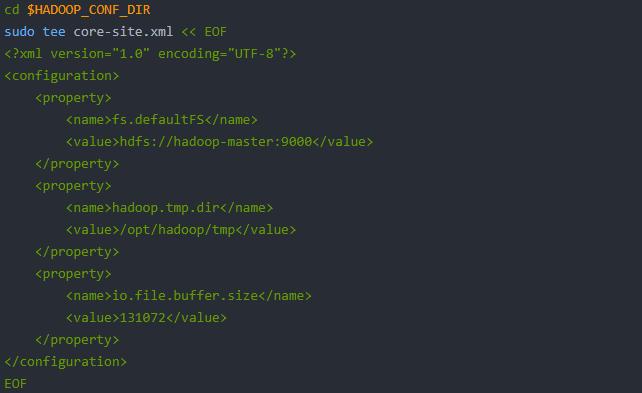
(2)配置核心文件
core-site.xml:
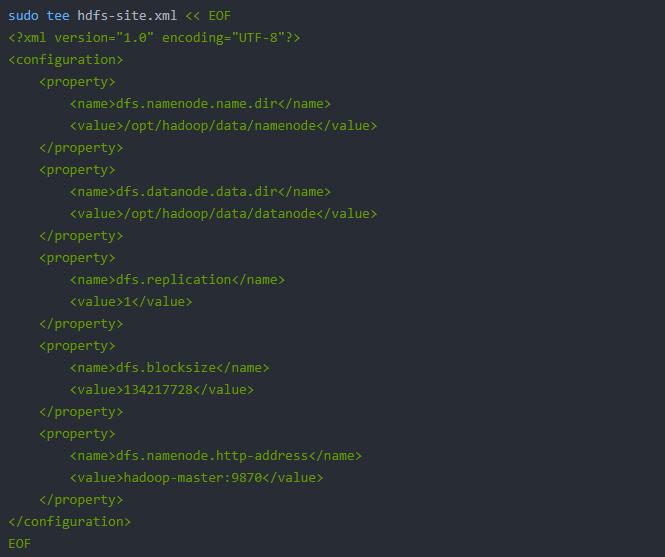
hdfs-site.xml:
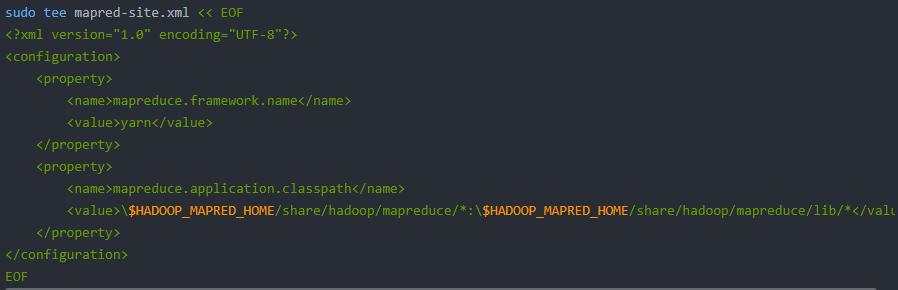
mapred-site.xml:
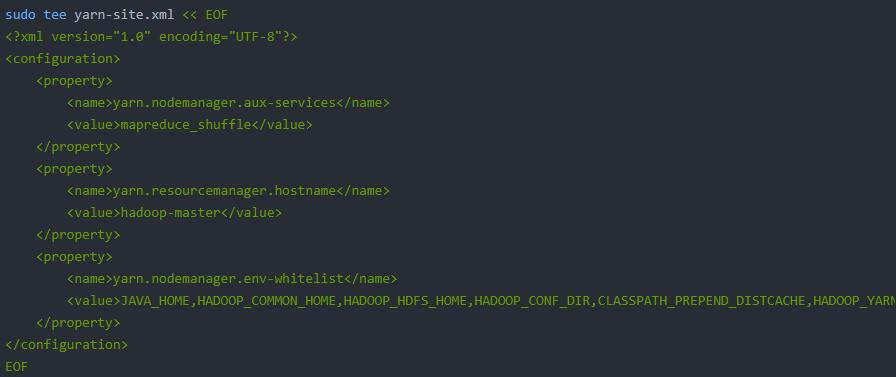
yarn-site.xml:
hadoop-env.sh:
# 修改hadoop-env.sh
echo “export JAVA_HOME=/opt/jdk1.8.0_41” | sudo tee -a hadoop-env.sh
4、集群初始化与启动验证
(1)创建数据目录
sudo mkdir -p /opt/hadoop/{tmp,data/namenode,data/datanode}
sudo chown -R hadoop:hadoop /opt/hadoop/{tmp,data}
(2)格式化HDFS(首次部署执行)
# 格式化NameNode
hdfs namenode -format -force
# 确认格式化成功
(3)启动Hadoop服务
(4)验证集群状态

四、高可用Hadoop集群部署
1、HA架构设计核心
高可用Hadoop集群解决单点故障问题,主要包括:
HDFS HA: Active/Standby NameNode + Shared Storage (QJM)
YARN HA: Active/Standby ResourceManager + ZooKeeper
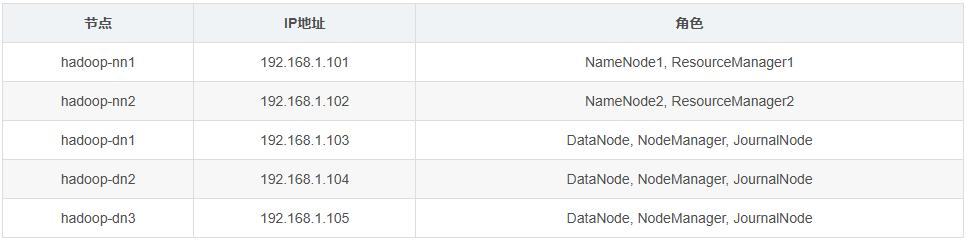
集群节点规划(以5节点为例):
2、前置环境配置
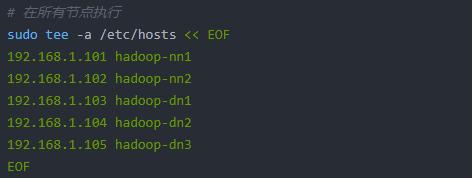
(1)节点网络与免密配置
所有节点配置静态IP与hosts文件(示例):
(2)SSH免密登录配置
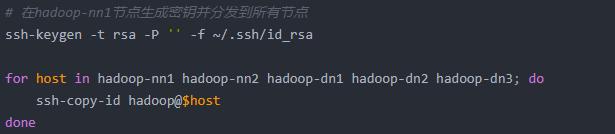
(3)部署ZooKeeper集群
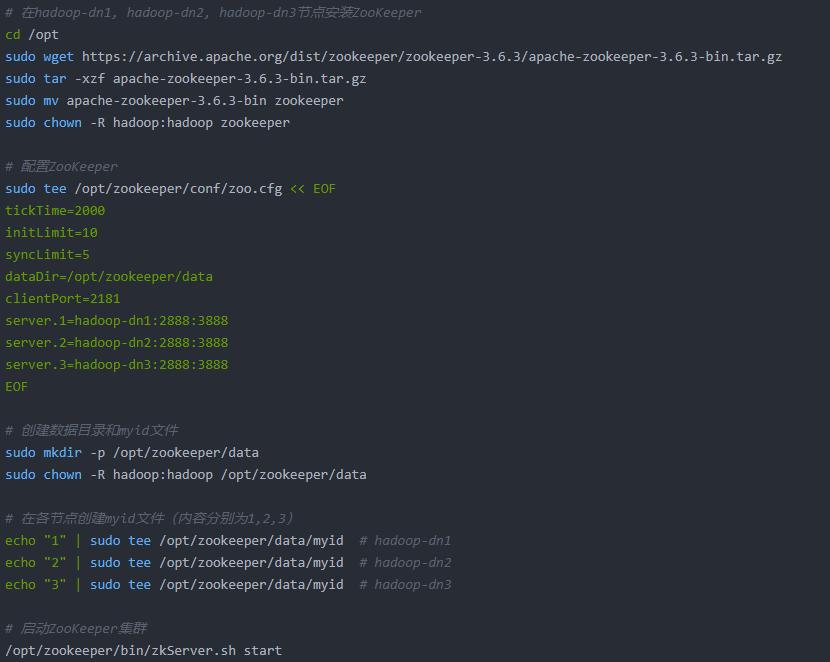
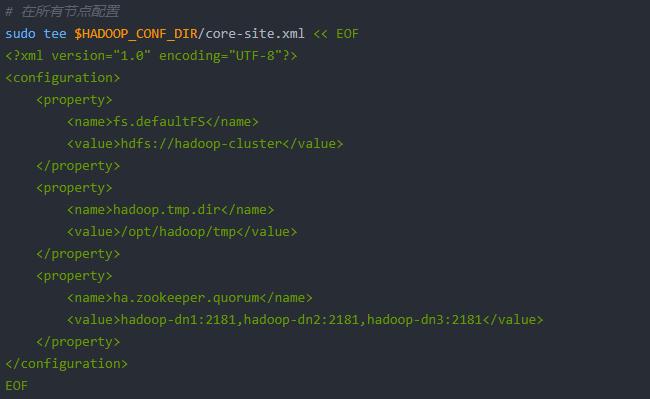
3、HDFS HA核心配置
(1)core-site.xml
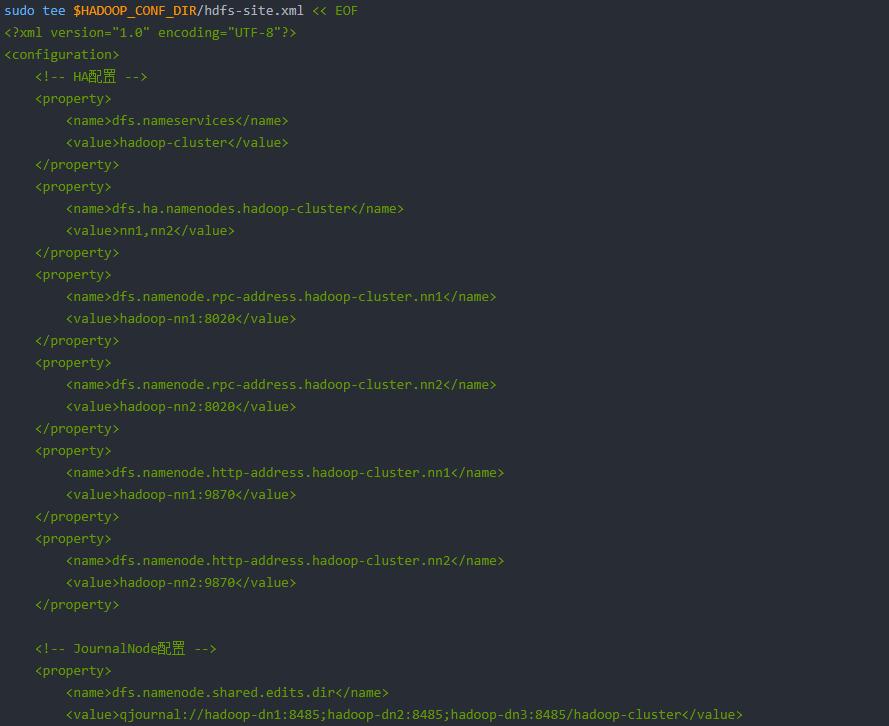
(2)hdfs-site.xml
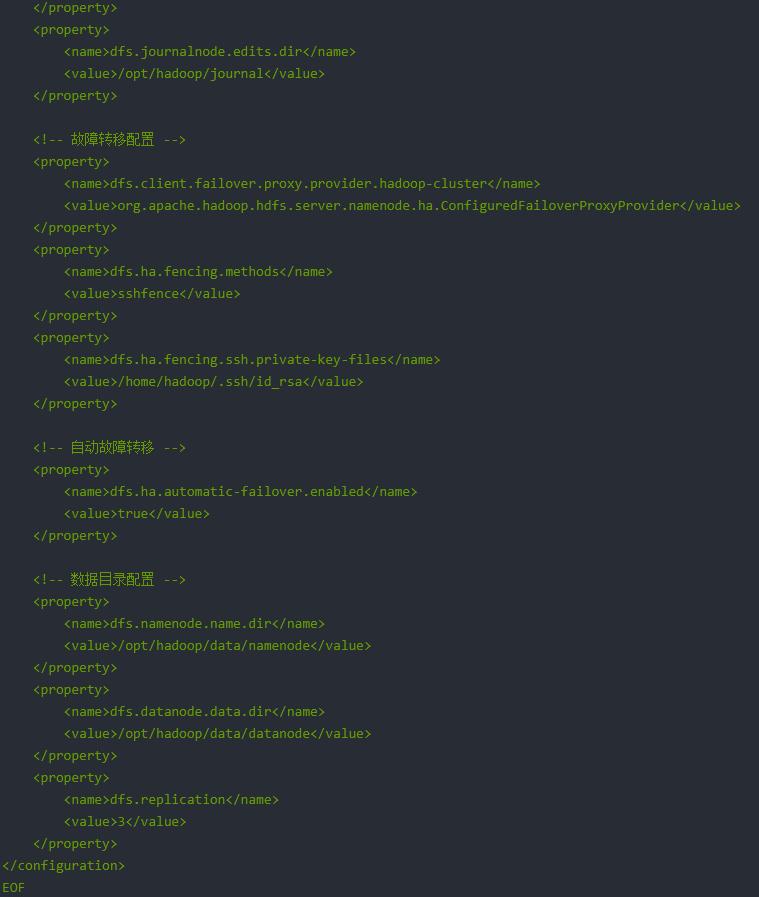
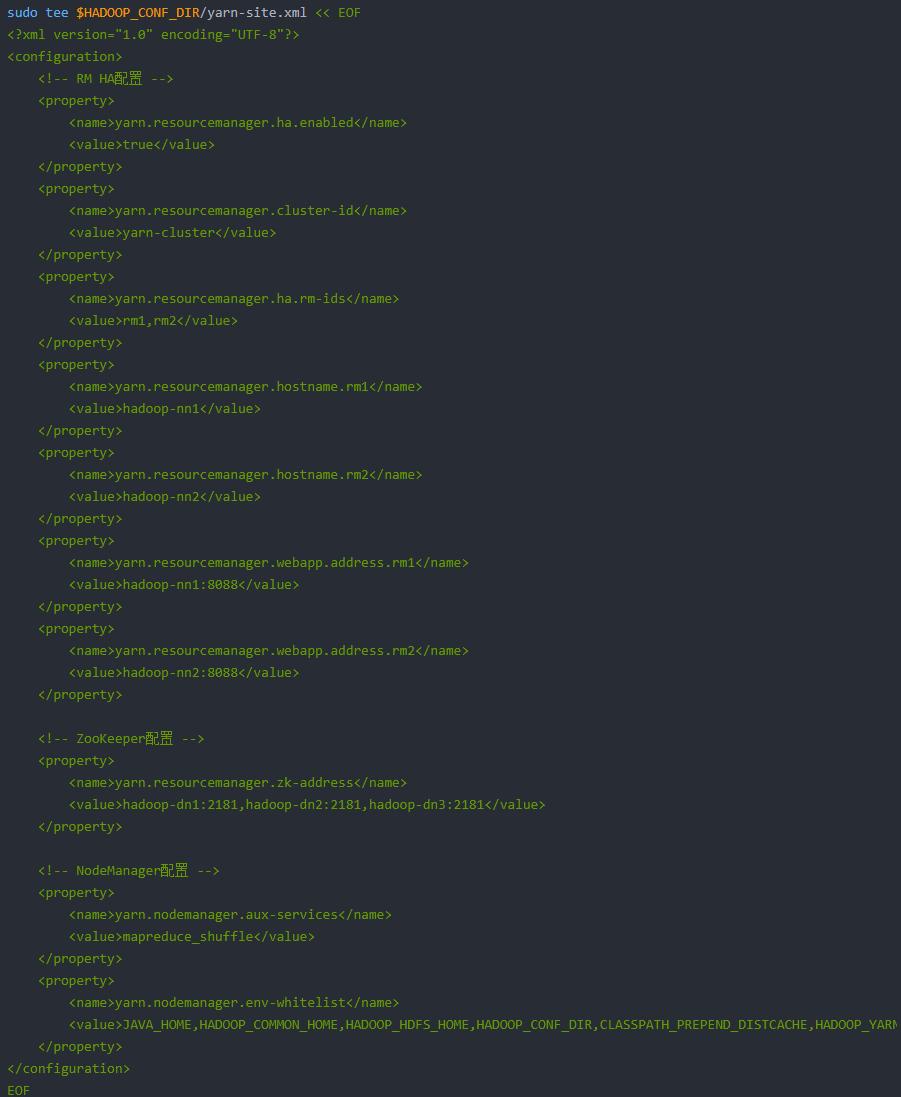
4、YARN HA核心配置(yarn-site.xml)
5、HA集群启动与验证
(1)在所有节点创建必要目录
sudo mkdir -p /opt/hadoop/{tmp,data/namenode,data/datanode,journal}
sudo chown -R hadoop:hadoop /opt/hadoop/{tmp,data,journal}
(2)启动JournalNode
# 在hadoop-dn1, hadoop-dn2, hadoop-dn3节点启动JournalNode
hdfs –daemon start journalnode
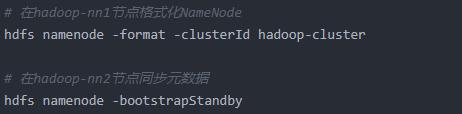
(3)格式化NameNode
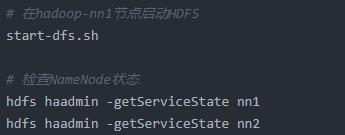
(5)启动HDFS HA
(6)启动YARN HA
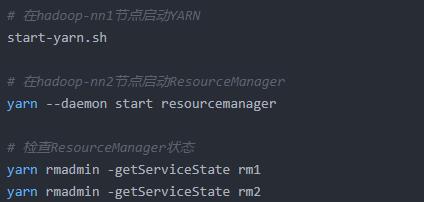
6、验证HA功能
(1)HDFS HA测试
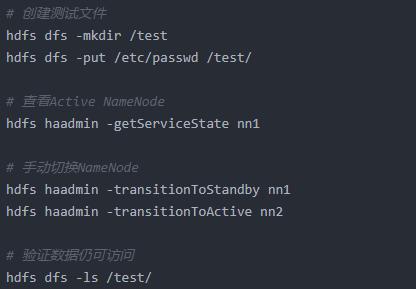
(2)YARN HA测试

-

广告合作
-

QQ群号:4114653



















