不久前Qwen3正式发布并开源了8款MoE模型和Dense模型,在代码、数学、通用能力等基准测试中表现出极具竞争力的结果,据说支持思考模式和非思考模式两种思考模式,提供119种语言和方言,因此在全球范围内获得了较高的关注和参与度。依托于阿里云函数计算FC算力,接下来将由站长百科详细介绍通过Serverless+AI开发平台FunctionAI的模型服务辅助部署Qwen3系列模型,无需任何代码。
一、支持的模型列表
部署方式说明:
- vLLM:大模型加速推理框架,优化内存利用率和吞吐量,适合高并发场景。
- SGLang:支持复杂的 LLM Programs,如多轮对话、规划、工具调用和结构化输出等,并通过协同设计前端语言和后端运行时,提升多 GPU 节点的灵活性和性能。
| 模型 | 部署方式 | 最低配置 |
| 通义千问3-0.6B | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-0.6B-FP8 | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-1.7B | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-1.7B-FP8 | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-4B | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-4B-FP8 | vLLM/SGLang/Ollama | GPU 进阶型 |
| 通义千问3-8B | vLLM/SGLang/Ollama | GPU 性能型 |
| 通义千问3-8B-FP8 | vLLM/SGLang/Ollama | GPU 性能型 |
| 通义千问3-14B | vLLM/SGLang/Ollama | GPU 性能型 |
| 通义千问3-14B-FP8 | vLLM/SGLang/Ollama | GPU 性能型 |
本篇文档将以通义千问 3-8B 模型演示部署流程。
部署前准备:
首次使用FunctionAI会自动跳转到访问控制快速授权页面,滚动到浏览器底部单击确认授权,等待授权结束后单击返回控制台。
函数计算FC提供的试用额度可用于资源消耗。额度消耗完后按量计费,对于本教程所涉及的Web服务,只在有访问的情况下才会产生费用。
二、阿里云FunctionAI是什么
FunctionAI是阿里云推出的一站式应用开发和生命周期管理平台,开发者可以通过Serverless架构来构建容器化、高弹性、免运维的云上应用,也可以通过AI大语言模型推动云上应用逐步升级为智能化应用,而FunctionAI的应用开发范式正是结合了Serverless和AI的两者优势,提供了丰富的Serverless + AI应用模板、先进的开发工具和企业级应用管理功能,帮助个人和企业开发者专注于业务场景。

1、极低成本模型托管服务:基于Serverless GPU算力模型服务,平均成本降低60%。
2、流程式开发先进工具:基于云工作流AI Studio开发能力,最高效率提升90%。
3、一键极速创建AI应用:海量高质量应用模板,面向不同客群,支持一键极速创建AI应用,解决AI应用开发者无从下手的困境
4、灵活组装,二次开发:基于丰富的云服务集成,原子化能力封装,自定义插件扩展,支持快速组装,沉淀业务资产,加速应用二次开发,满足业务定制化需求。
三、一键部署教程Qwen3教程
接下来将通过通义千问3-8B模型 + OpenWebUI部署Qwen3。
1、创建项目
首先通过阿里云云原生应用开发平台CAP创建项目。
阿里云官网:点击直达

2、部署模板
在阿里云FunctionAI平台内搜索“Qwen3”,点击“基于 Qwen3 构建 AI 聊天助手”模版并部署。

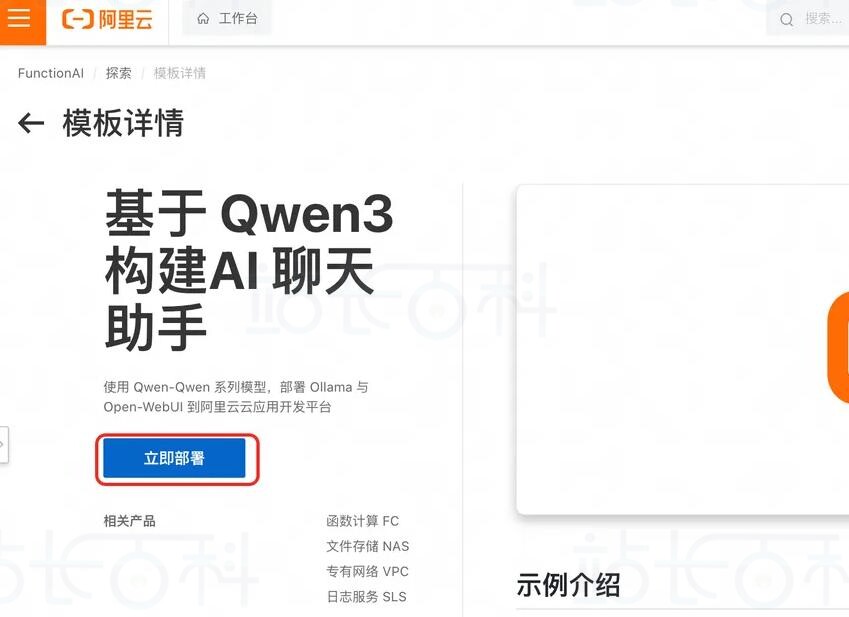
3、选择Region并部署应用,整个过程大概10分钟左右。

4、验证应用
部署完毕后需要验证应用,点击Open-WebUI服务,在访问地址内找到“公网访问”。

在OpenWebUI界面验证Qwen模型对话。

以上就是基于阿里云一站式应用开发和生命周期管理平台一键部署Qwen3的全过程。
相关推荐:
-

广告合作
-

QQ群号:4114653